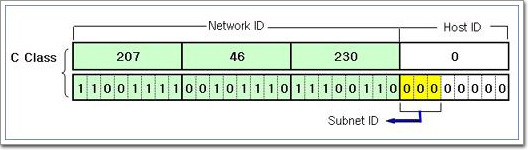
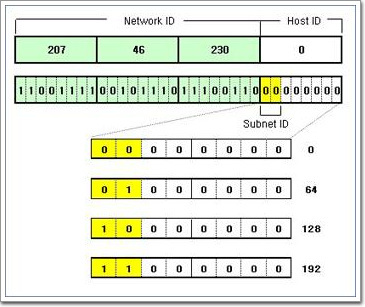
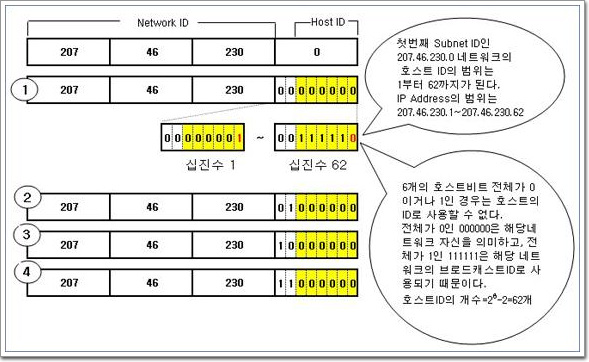
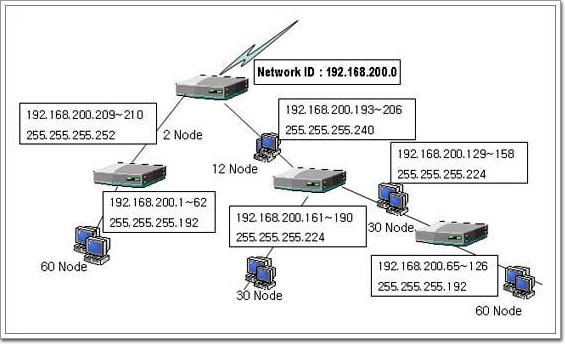
4-2. DHCP서버의 구현 Windows Networking2008. 11. 13. 21:28
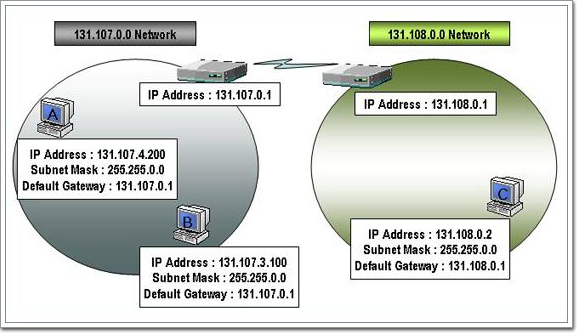
DHCP서비스를 구현하기 전에 가장 먼저 할 일은 네트워크에서 IP Address관리방법에 대한 결정이 있어야 한다. 클래스 전체를 하나의 네트워크에서 쓸 것인지, 서브넷팅을 통해서 사용을 할 것인지에 대한 결정이 되었다면 이번에는 각 네트워크마다 사용할 호스트ID의 범위중에서 어떠한 IP를 라우터에게 할당을 하고, 어떠한 IP를 서버들에게 할당을 할 것이고, 어떠한 IP를 DHCP를 통해서 클라이언트에게 할당한 것인지 등을 결정하는 과정을 의미한다. 간단하게 A회사의 IP Address 관리테이블을 만들어 보았다.

<그림4-4. A회사 IP Address 관리 테이블>
이제 클라이언트를 위한 DHCP서비스를 구현해 보도록 하겠다. 네트워크에는 DHCP서버가 있어야 하고, 당연히 클라이언트도 구성이 되어야 한다. DHCP서버는 네트워킹 서비스이므로 서버제품군에서 구현될 수 있다. 먼저 DHCP서버를 설정해 보겠다.
Windows Server 2003이 설치될 때 DHCP, DNS 등의 네트워크 서비스는 기본적으로 설치되지 않는다. 구현을 하고자 할 때 추가로 설치를 해야 하는데 제어판의 프로그램 추가/제거를 통해서 설치할 수 있다.
4-2-1. DHCP서비스 설치
<그림4-5. DHCP서비스 설치>

제어판의 프로그램추가/제거를 열고 "Windows구성요소 추가"를 선택하면 잠시후 "Windows구성요소"창이 열린다. 리스트를 찾아보면 "네트워킹 서비스"가 있는데 이것은 DHCP, DNS, WINS 등의 네트워킹 서비스들 전체의 묶음이다. -네트워킹 서비스 앞의 체크박스를 클릭하면 전체 네트워킹 서비스들이 설치가 되므로 체크박스 대신에 글자 부분을 클릭한다.- <자세히>버튼을 누르면 리스트에서 "DHCP(동적 호스트 구성 프로토콜)"를 찾을 수 있다. 체크하고 <확인>을 누르면 설치를 시작한다. Windows서버의 원본CD-Rom이 요구된다. 원본CD중에서도 i386 폴더가 셋업을 위한 폴더이다. 원본CD위치를 묻는 메시지가 뜬다면 원본CD를 넣고 i386폴더를 지정해 주면 셋업이 시작된다.
잠시후 설치가 끝났다는 메시지가 나오면 DHCP서비스가 추가된 것이다. 관리도구에 "DHCP" 라는 관리메뉴가 추가된 것을 볼 수 있는데, 클릭하면 <그림4-6>과 같은 그림을 만날 수 있다.

그림을 보면 친절하게도 오른쪽 패널에 설치방법에 대해서 설명을 해 주고 있다. 그리고 왼쪽패널의 서버이름 부분을 보면 아래쪽으로 향한 빨간색 화살표를 확인할 수 있다. DHCP서비스가 멈춰져 있다는 것을 말한다.
4-2-2. DHCP권한부여 작업 - (Active Directory 도메인 환경에서만 적용됨)
<그림4-6>에서 오른쪽 패널의 설명을 읽어보면 "DHCP서버가 IP 주소를 발급하기 전에 범위를 만들고 DHCP서버에 권한을 부여해야 합니다"라고 이야기한다. 범위라 하면 클라이언트들에게 발급할 IP Address를 구성하라는 뜻인 것 같은데, 권한을 부여하라구? 이렇듯 Windows Server 2003 DHCP서비스는 설치만 한다고 동작하는 것이 아니다. DHCP서버가 동작할 수 있도록 권한이 부여가 되어야만 DHCP서버는 동작을 하게 된다.
이것은 아무나 할 수 있는 작업은 아니다. 도메인에서 이러한 작업을 할 수 있는 사용자는 기본적으로 "관리자"로 제한된다. 정확히 말하면 도메인의 "Enterprise Admins"라는 그룹의 멤버가 이러한 작업을 할 수 있다.
이것은 어디까지나 회사의 네트워크 환경이 Active Directory도메인으로 구성되어 있을 때의 상황이다. 만일 회사가 도메인 모델을 채택하지 않고 워크그룹 환경으로 구성되어 독립된 서버에서 DHCP서비스를 구현하고 있다면 이 과정은 건너 뛰고 바로 다음 작업인 DHCP서버 구성으로 넘어간다.
<그림4-7. DHCP서버 권한부여>

DHCP서버에 권한을 부여하기 위해서는 DHCP관리콘솔을 이용한다. 관리콘솔에서 서버이름을 클릭하고 마우스 오른쪽 버튼을 누른후 "권한부여"를 선택하면 간단히 권한이 부여된다. 권한이 부여된 DHCP서버의 리스트를 확인하거나, 여러대의 DHCP서버를 관리하고자 한다면 다른 방법도 있다. 관리콘솔에서 DHCP항목을 클릭하고 마우스 오른쪽 버튼을 누르면 "권한이 부여된 서버관리"라는 메뉴를 볼 수가 있다<그림4-8>
<그림4-8. 권한이 부여된 DHCP서버 관리메뉴>

<그림4-8>의 메뉴를 클릭하면 Active Directory에서 권한이 부여된 DHCP서버의 리스트를 볼 수가 있고 다른 DHCP서버에게 권한을 부여하거나 리스트에서 DHCP서버를 제거하는 것도 가능하다.
<그림4-9.권한이 부여된 DHCP서버관리>

DHCP서버에게 권한을 부여하고 나면 관리콘솔의 왼쪽패널의 서버이름 옆에 위로 향한 녹색 화살표를 확인할 수 있다. DHCP서비스가 시작된 것이고, 오른쪽 패널의 설명도 처음 DHCP서비스를 추가했을 때와는 다른 설명을 보여주고 있다. <그림4-10>
<그림4-10. DHCP서비스가 시작된 DHCP관리콘솔>

4-2-3. DHCP서버 구성
DHCP서비스가 시작되면 DHCP서버는 브로드캐스트를 통해서 DHCP Discover 메시지를 날리는 클라이언트에게 IP Address를 발급해 주어야 하는데 이렇게 하기 위해서는 당연히 DHCP서버는 클라이언트를 위한 IP Address Pool을 가지고 있어야 한다. IP Address 발급을 위한 범위를 만들고 클라이언트를 위한 추가설정을 해 주어야 하는 것이다.
예제에서 DHCP서비스를 하는 blueapple이라는 서버는 192.168.5.0 네트워크를 위해 IP를 발급하고자 한다.
<그림4-11. 새 범위 추가 메뉴>

서버이름을 클릭하고 마우스 오른쪽 버튼을 눌러서 "새 범위"를 추가한다.
<그림4-12.새 범위 추가-범위이름>

범위이름을 입력해야 하는데, 이것은 실제 서비스와는 아무런 상관이 없다. 관리자가 알아보기 쉽게 이름과 설명을 주면 된다. 여러개의 네트워크를 DHCP서버가 지원해야 할 때 각각의 범위를 구별하기 쉽게 이름을 부여한다. 예제에서는 '2층 네트워크'라고 입력했다.
<그림4-13. 새 범위 추가-IP주소 범위>

DHCP클라이언트에게 발급할 IP Address의 범위와 적합한 서브넷마스크를 입력해야 한다. 하나의 DHCP서버는 하나의 네트워크당 하나의 IP범위 관리영역만 가질 수가 있다는 것을 염두에 둔다. 만일 192.168.5.11~100까지가 DHCP클라이언트용 IP Address라고 가정을 했을 때, 51~60까지가 서버들에게 고정IP로 발급한 부분이라서 제외해야 한다고 하더라도 192.168.5.11~50까지의 하나의 범위를 만들고 추가로 192.168.5.61~100까지의 영역을 만들 수는 없다. 그럴 경우에는 일단 전체범위를 잡은 다음에 고정IP로 사용할 IP가 범위에 포함되어 있다면 다음 과정에서 그 특정범위만큼을 제외하는 방법을 사용해야
<그림4-14. 새 범위 추가- 제외주소 추가>

필요하다면, IP범위중에서 제외할 특정 IP나 IP범위를 추가한다. DHCP서버는 단순한다. 클라이언트가 IP를 요청했을 때 자신의 IP범위중에서 사용가능한 IP를 골라서 망설이지 않고 IP 발급을 한다. 만일 Web서버에게 192.168.5.20 IP Address가 셋팅되어 있다고 가정을 했을 때, DHCP서버의 설정에192.168.5.20 IP가 사용가능한 상태로 되어 있다면 DHCP클라이언트는 192.168.5.20 IP를 발급받게 된다.
이 경우 네트워크에서 이미 사용되고 있는 IP를 발급받은 해당 클라이언트는 정상적으로 TCP/IP를 사용할 수가 없게 된다. 관리자가 해결해 주면 되겠지만 간혹의 경우에는 먼저 이 IP Address가 설정된 Web 서버가 제대로 동작하지 못하는 경우가 발생할 수도 있으므로 IP Address의 충돌이 생길 소지가 있는 부분에는 특별히 신경을 써야 한다.
Windows2000 이상의 서버에서 DHCP서비스를 구현한다면 서버의 고급옵션에서 ‘충돌감지시도횟수’를 할당하여 DHCP클라이언트에게 IP를 할당하기 전에 먼저 IP사용유무를 테스트하게 할 수도 있다. 이번장의 후반부에서 다시 한번 언급된다.
<그림4-14>에서 보듯이 제외할 주소를 추가하는 방법은 두가지이다. IP Address를 하나씩 추가할 수도 있고, 범위를 지정해서 추가하는 방법이 있다.
<그림4-15. 새 범위 추가- 임대기간 결정>

클라이언트에게 IP를 발급할 때 결정해 줄 임대기간을 지정한다. 기본값은 8일이다. 임대기간이 길어질수록 IP Address 갱신주기가 길어질 것이기 때문에 IP Address가 충분히 여유가 있다면 기간을 더 길게 설정하는 것이 좋다. 네트워크에서 DHCP트래픽의 비중은 극히 일부분이지만 DHCP 관련된 네트워크 트래픽을 최소화 할 수 있는 방법이 된다. 반대의 상황이라면? 당연히 기간을 줄여야 할 것이다.
<그림4-16. 새 범위 추가 - DHCP옵션구성>

지금까지 위에서는 클라이언트에게 발급할 IP Address와 Subnet Mask를 구성하였는데, 클라이언트들의 TCP/IP설정에는 Default Gateway, DNS, WINS등의 추가 설정이 필요하다. DHCP서버는 이러한 사항들을 'DHCP옵션'으로 처리해 주고 있다. DHCP옵션을 구성하는 그림이 나오는데 지금 구성할 수도 있고, 나중에 추가로 작업하는 것도 가능하다. "아니오"를 통해서 마법사를 마쳐도 기본적인 DHCP구성은 끝난 것이다. 계속 구성을 해 보도록 하겠다.
<그림4-17. 새 범위 추가 - DHCP옵션구성 - Router>

클라이언트에게 할당할 Router, 즉 Default Gateway로 설정될 IP Address를 입력하고 <추가>버튼을 누릅니다.
<그림4-18. 새 범위 추가 - DHCP옵션구성 - DNS서버>

DNS를 구성하는 과정인데 <그림4-18>의 예제처럼 IP주소만 입력해 주어도 동작하는 데는 문제가 없다. 그렇지만 도메인 환경에서의 작업을 고려한다면 부모도메인의 항목에도 도메인 이름을 입력할 필요가 있다. 예를 들어서 사용자가 속한 도메인이 secure.pe.kr 이라고 하면 '부모도메인'항목에 'secure.pe.kr'이라고 입력을 한다. 그렇게 해 주면 사용자가 hostA.secure.pe.kr 이라는 이름의 호스트를 찾고자 할 때 hostA 라고만 입력을 해도 실제 DNS에 쿼리가 날아갈 때는 hostA.secure.pe.kr 라는 이름으로 요청을 한다.
또한 DNS서버의 IP를 하나만 주는 것보다는 2개를 할당하여 하나의 DNS서버가 문제가 있을 경우를 대비하는 것이 좋다. DHCP클라이언트는 DNS서버의 IP를 2개를 가지게 되며 첫 번째 DNS서버가 문제가 있을시 두 번째 DNS서버를 통해서 호스트이름을 IP Address로 변환하는 작업을 처리할 수 있다. 회사에 DNS서버가 하나만 구현이 되어 있다면 추가로 ISP의 DNS등, 외부의 DNS서버를 두 번째 DNS서버로 셋팅하는 것도 하나의 방법이다. DNS는 아주 중요한 서비스중의 하나이다. DNS에 대해서는 5장에서 자세히 다루도록 하겠다.
<그림4-19. 새 범위 추가 - DHCP옵션구성 - WINS서버>

WINS서버의 IP를 입력한다. 역시 하나보다는 두 개를 사용하는 것이 좋다. 물론 네트워크에 WINS서버가 적어도 2개 이상 있다는 전제가 따라야 한다. WINS서버는 "NetBIOS이름풀이"를 위해 필요한 서버이다. 6장에서 자세히 다룬다.
<그림4-20. 새 범위 추가 - DHCP옵션구성 - 범위 활성화>

이제 옵션구성도 끝났다. 192.168.5.0 네트워크의 IP범위를 활성화 할 필요가 있다. 활성화 하기 전까지는 DHCP서버는 클라이언트의 요청에 응답하지 않다. 만일 추가로 구성을 더 해야 할 필요가 있다면 "아니오. 나중에 활성화하겠다."를 선택해서 DHCP서버가 IP를 발급하지 못하도록 한다. 나중에 DHCP관리콘솔을 통해서 얼마든지 활성화 작업은 가능하다.
<그림4-21. 새 범위 추가 - 새 범위 마법사 완료>

DHCP서버에 '새 범위 마법사'를 완료하는 그림이다.
<그림4-22. DHCP서버에 범위가 추가된 그림>

<그림4-22>에서는 blueapple.secure.pe.kr 이라는 이름의 DHCP서버에 192.168.5.0 네트워크의 IP범위가 설정된 그림을 보여준다. 왼쪽패널의 '주소풀'을 클릭하면 오른쪽으로 IP주소 범위를 보여주는 그림을 볼 수 있다. 그림을 보면 192.168.5.11부터 192.168.5.100 까지가 범위로 되어 있고, 두 번째 리스트에는 192.168.5.20이 제외된 IP주소임을 보여준다. 결국 이 설정에서는 192.168.5.11~192.168.5.19, 192.168.5.21~192.168.5.100까지 총 89개의 IP가 사용가능하다는 것을 알 수 있다.
<그림4-23. DHCP 범위 옵션 확인>

DHCP관리콘솔의 192.168.5.0 범위의 '범위옵션'을 눌러보면 오른쪽 패널에 위에서 설정한 몇가지 DHCP옵션이 나오는 것을 확인할 수 있다. 이것은 마이크로소프트의 네트워크를 구축할 때 항상 따라다니는 기본 DHCP옵션들이다.
|
* DHCP서버 구성시 기본적인 옵션 003 라우터 006 DNS서버 044 WINS/NBNS서버 046 WINS/NBT노드유형 |
각 옵션값들의 설명은 각각의 장에서 따로 다루도록 한다.
이제 DHCP서버의 구성은 마쳤다. 다음엔 DHCP클라이언트의 설정을 구성해야 할 차례이다. 그래야 이 DHCP서버로부터 TCP/IP 구성을 받아갈 수 있다.