Network Layer ; 계층은 패킷의 주소를 결정하고, 라우팅을 하는 과정
- IP (Internet Protocol) : 패킷 전송 담당자
IP역시 UDP처럼 "연결없는 전송서비스 (Connectionless delivery service)"를 제공한다. "연결없는 전송서비스"라는 것은 패킷을 전달하기 전에 대상 호스트와 아무런 연결도 필요하지 않다는 것을 의미한다. 또, IP는 전송을 위해서 최선을 다하지만 책임은 지지 않기 때문에 그것에 대한 책임은 상위의 계층의 프로토콜(TCP)이 담당하거나, 어플리케이션 차원에서 해결을 해야만 한다.
어플리케이션이 만든 데이터를 상위의 프로토콜로부터 전달받았을 때, IP는 그 패킷에 IP자신의 헤더정보를 추가한다. IP헤더에는 많은 정보가 들어 있다. Internetwork세상을 돌아다니면서 수많은 라우터를 건너 원하는 목적지까지 데이터를 실어 나르기 위해서는 많은 헤더정보가 필요한 것이다.
<그림1-9. 네트워크 모니터로 캡처한 그림 – IP 패킷>
IP패킷에는 상당히 많은 헤더정보가 있다. 이 정보를 가지고 전세계에 어디에 있는지도 모르는 서버들을 찾아다니는 인터넷 환경까지 지원을 하고 있으니 조금 많은 것이 당연하겠다는 생각이 든다. 경중을 따진다는 것이 무의미하겠지만 많은 헤더 중에서 가장 중요한 헤더정보는 IP Address라고 할 수 있다. IP헤더에는 자신의 IP Address, 목적지의 IP Address 등의 Address정보, 상위의 계층 중 어느 프로토콜을 이용할 것인지를 알려주는 프로토콜 정보, 패킷이 제대로 왔는지를 확인하기 위한 용도로 사용이 되는 Checksum 필드, 네트워크 상에서 존재하지 않는 호스트를 찾기 위해 끝없는 방황을 하는 것을 막기 위한 TTL등의 정보가 들어 있다.
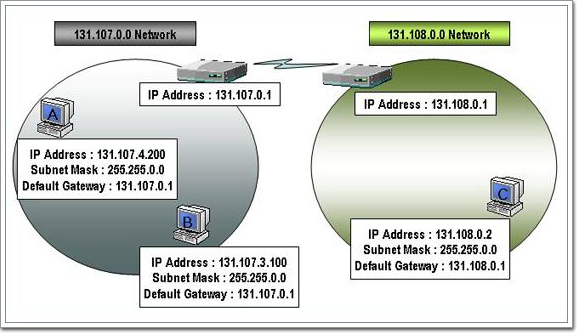
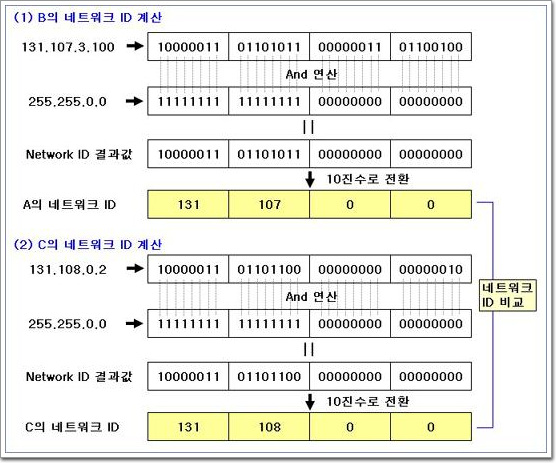
IP가 하는 일은 이러한 헤더정보를 이용하여 패킷을 전달하는 역할을 한다. 그 때 참조하는 것이 바로 라우팅 테이블이며, 만약에 라우팅 테이블에 정보가 없다면 자신의 기본 게이트웨이로 설정되어 있는 라우터에게 패킷을 전달한다. 갑자기 조금 다른 내용이 나왔는데 잘 이해가 안 돼도 괜찮다. 이 부분에 대해서는 다음 장에서 자세히 설명한다.
일반적인 호스트의 IP와는 달리 라우터의 IP는 몇가지 일을 더 하고 있다. 우리가 사용하는 각각의 컴퓨터들도 IP를 사용하고, 이들 컴퓨터들이 서로 다른 네트워크간에 통신이 되려면 라우터가 있어야 하는데, 이들도 역시 IP라는 것을 사용한다. 다만 하는 역할이 조금 다를뿐이다.
첫 번째는 IP호스트로부터 받은 패킷의 헤더에 들어 있는 TTL(Time to Live)을 감소시킨다. 보통 1을 감소시키지만, 라우터가 상당히 혼잡한 상태라면 1이상이 감소될 수도 있다. 만일 TTL이 "0"이 된다면 그 패킷은 더 이상 라우팅이 되지 않고 버려진다. 이렇게 라우터들이 IP패킷의 TTL을 감소시킴으로써 TTL이 "0"이 되는 시점이 되면 더 이상 패킷을 전달시키지 않기 때문에, 궁극적으로는 잘못된 IP정보를 가진 패킷이 무한루프를 돌아 인터넷이 이러한 잘못된 패킷들로 가득차서 정상적인 통신을 방해하는 것을 막아주게 된다.
두 번째, 그리고 나면 IP Router는 헤더정보에서 TTL이 바뀌었기 때문에 거기에 맞는 Checksum을 다시 계산한다.
세 번째, 패킷을 전달해야 할 라우터의 MAC Address를 알아낸다. 이렇듯 우리가 사용하는 컴퓨터에 설치된 NIC(Network Interface Card; 네트워크 어댑터 카드)뿐만이 아니라 라우터도 역시 NIC를 가지고 있으며 그들도 역시 MAC Address 주소를 가지고 네트워크에서 식별된다.
네 번째, 해당 라우터로 패킷을 전달한다. 이 과정을 바로 라우팅(Routing)이라고 하는 것이며, 라우팅을 담당하는 하드웨어를 우리는 "라우터"라고 부른다. Windows 서버 OS를 가지고도 라우터를 구현할 수 있다. 다만 여러분들이 일상적으로 ‘라우터’라고 부르는 것은 라우팅 기능을 전문적으로 구현하도록 만들어진 하드웨어 장비를 일컫는다.
인터네트워크 상의 모든 라우터들은 위의 4가지 작업을 반복하게 되며, 결국 원하는 목적지의 라우터까지 도착하고, 그 라우터를 통해서 목적지의 호스트에게까지 데이터를 전달시킬 수 있게 된다.
이번에는 라우터가 전송할 수 없는 너무 큰 크기의 패킷을 받았다고 가정을 해 보겠다. 이 때도 역시 라우터는 여전히 패킷을 전송시킬 수 있는 방법을 포함하고 있다. 라우터의 IP는 패킷을 수용할 수 있는 작은 조각(Chunk)으로 나눈다. 그렇게 작은 크기로 나누어서 전송하게 되면, 받는 호스트에서는 잘게 나뉜 패킷을 원래 크기로 조합하는 작업을 하여 상위의 어플리케이션에 데이터를 전송한다. 이 과정을 가리켜서 fragmentation(조각내기)와 reassembly(재조립)이라고 한다.
예를 들면 이더넷과 토큰링 등 서로 다른 네트워크가 조합된 환경을 들 수가 있다. 만일 1.5KB크기의 IP패킷이 라우터로 들어 왔을 때, 라우터가 전송해야 할 네트워크에서는 1.5KB를 수용할 수 없고 단지 500byte의 크기만을 지원한다고 해 보겠다. 그 때 라우터의 IP는 1.5KB의 원본패킷을 500byte 단위로 잘게 쪼개게 될 것이다. 결국 3개의 패킷이 생성이 될 것이고, 라우터는 이 3개의 패킷을 전송한다.
이때 만일 라우터의 IP가 이렇게 나뉘어진 패킷을 아무 생각없이 단순히 전송을 해 버린다고 생각을 해보면 도대체 받는 호스트 입장에서는 답답한 노릇이 아닐 수 없다. 도대체 이것이 조각난 패킷인지 온전한 패킷인지, 만일 조각난 것을 알았다면 어떻게 조립을 해야 할지 알 수 있는 방법이 필요한 것이다. 그러한 이유로 패킷을 조각내는 라우터의 IP는 조각낸 패킷에 수신 호스트가 구분할 수 있는 데이터를 추가한다. flag, fragment ID, fragment Offset이 바로 그것이다. flag는 이 패킷이 완전한 패킷이 아닌 조각나 있음을 보여준다. fragment ID는 조각난 패킷들이 원래 같은 패킷의 일부분이었음을 보여주는 정보이다. 동일한 패킷에서 조각난 패킷들은 같은 fragment ID를 가지게 되며 fragment Offset은 수신측 호스트가 어떻게 조각난 패킷을 조립할 것인지를 알려준다. 결국 조각들의 순서를 알려주는 것이다.
수신측 호스트는 이러한 패킷을 fragment offset순서에 따라서 조립을 한 다음 완전한 패킷을 만들고 상위 계층의 프로토콜인 TCP나 UDP에게 보내게 된다. 물론 이때 TCP에게 보내야 할 것인지 UDP에게 보내야 할 것인지의 정보는 IP헤더에서 제공을 해 주고 있다. TCP/IP를 공부하다 보면 대단하다는 생각이 든다. TCP/IP라는 프로토콜도 사람이 만든 것이긴 하지만 대단히 논리적인 사고를 하는 사람들의 작품이라는 생각이다.
- ARP (Address Resolution Protocol)
단순하지만 아주 중요한 내용이다. 지금까지의 과정을 정리해보면 응용프로그램이 데이터를 만들었고 이 데이터를 TCP나 UDP에게 내려보냈다. TCP나 UDP는 자신들이 원본데이터에 각각 “헤더”라고 부르는 정보를 추가한 다음 이 패킷을 전달하는 역할을 하는 IP에게 내려보내고, IP는 상대방 컴퓨터의 IP Address를 근거로 해서 IP Packet이라는 것을 만들어 내게 된다. 많은 과정이 있었지만 아직까지는 실제 통신이 일어난 것이 아니다. 실제 통신이 일어나기 위해서는 어떤 형태로든 상대방 컴퓨터에게 이 패킷을 전달해야 할 것이다. 그 방법으로 우리는 케이블이 연결된 네트워크 어댑터 카드(NIC)를 이용한다.
문제는 이 네트워크 어댑터 카드는 IP Address라는 논리적인 주소를 통해서 통신을 하지는 못하는데 있다.
네트워크 어댑터 카드는 위에서 시키는 대로 그대로 행동에 옮길 뿐이다. 보다 상위 계층에서 사용하는 IP Address는 뭔지 모르는게 당연하다. 이들은 MAC Address라는 물리적인 주소를 이용해서 통신을 진행한다. 다시 한번 정리를 해 보면, IP가 패킷을 라우팅할 때는 물리적인 통신을 담당하는 네트워크 어댑터 카드 (NIC)가 인식할 수 있는 하드웨어 어드레스가 필요하게 되는데 이것이 바로 MAC Address이며, IP는 이러한 MAC Address를 알아 내야만 통신을 할 수가 있게 되는 것이다. 이어지는 Physical Layer에서 다시 한번 설명하겠다. 일단은 “IP Address가 네트워크 통신의 다음단계를 진행하기 위해서는 MAC Address를 알아내야만 한다”라고 정리해 둔다.
이러한 IP의 요구에 해답을 제공하는 것이 바로 ARP (Address Resolution Protocol)이다. 통신을 원하는 상대방 호스트의 MAC Address가 요청될 때 가장 먼저 ARP Cache를 찾아서 그곳에 원하는 IP Address와 MAC Address의 정보가 있는지를 알아보게 된다. 최근에 해당 호스트와 통신을 했던 적이 있다면 ARP Cache에는 그러한 정보가 남아 있기 때문이다. 만약 해당 IP Address와 MAC Address가 매핑된 정보가 ARP Cache에 없다면, ARP는 목적지의 IP Address를 근거로 하여 MAC Address를 찾기 위한 ARP요청 프레임을 만들고, 그것을 브로드캐스트(Broadcast)통신방법을 이용해서 네트워크에 뿌리게 된다. 브로드캐스트이기 때문에 같은 네트워크에 존재하는 모든 호스트가 ARP요청을 받게 되지만, 결국 응답하는 호스트는 해당 IP Address와 일치하는 IP를 가진 호스트만이 응답을 하고 나머지는 버려지게 된다. 그 응답으로 ARP는 상대방 IP주소를 이용해서 MAC Address를 알아내게 되었다.
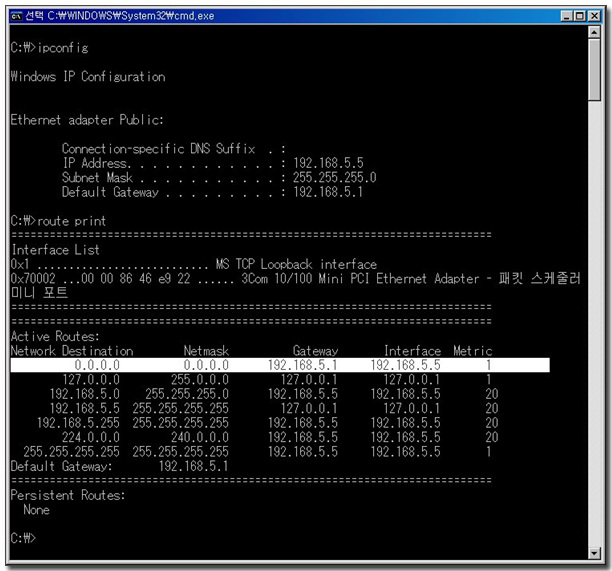
이런 ARP의 도움을 받아서 IP는 목적지 호스트의 MAC Address를 알아내기 때문에 MAC Address를 기반으로 하는 통신을 할 수가 있는 것이다. ARP정보를 들여다 볼 수 있는 유틸리티가 기본적으로 제공된다. 유틸리티 이름 역시 arp.exe 인데, 이것을 통해서 간단하게 ARP 정보를 조회해 보도록 하겠다. Arp는 명령프롬프트에서 동작하는 유틸리티이다. 명령프롬프트에 접근하기 위해서는 “시작à프로그램à보조프로그램à명령프롬프트”를 실행하거나, 시작à실행창에 “cmd”라고 입력하면 된다. 시스템 관리자라면 명령프롬프트(Command Prompt)에서 해야 하는 일들이 아주 많다. 그만큼 자주 들락거려야할 것인데, 필자의 경험으로는 cmd를 입력해서 접근하는 것이 가장 편하다.
앞으로 명령프롬프트를 통해서 작업한 내용들을 여러 번 볼 수 있을 것이다. 굵은 글씨로 보이는 부분이 직접 키보드를 통해서 입력한 내용이고 보통 글씨로 보여지는 것은 명령에 따른 결과로 나온 그림이다. 괄호안의 내용은 부연설명이다.
|
Microsoft Windows XP <Version 5.1.2600>
(C) Copyright 1985-2001 Microsoft Corp.
C:\Documents and Settings\wssong>ping 192.168.5.1 (192.168.5.1 IP Address를 사용하는 호스트에게 Ping을 이용한 연결테스트를 하고 있다.)
Pinging 192.168.5.1 with 32 bytes of data:
Reply from 192.168.5.1: bytes=32 time<1ms TTL=128
Reply from 192.168.5.1: bytes=32 time<1ms TTL=128
Reply from 192.168.5.1: bytes=32 time<1ms TTL=128
Reply from 192.168.5.1: bytes=32 time<1ms TTL=128
Ping statistics for 192.168.5.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0ms
C:\Documents and Settings\wssong>arp –a (arp cache 를 보여달라는 명령)
Interface: 192.168.5.3 --- 0x3
Internet Address Physical Address Type
192.168.5.1 00-00-e8-78-de-90 dynamic (ping을 이용해서 통신을 했던 컴퓨터의 IP Address와 MAC Address의 매핑 테이블을 보여준다.)
C:\Documents and Settings\wssong>arp –d (arp cache 를 삭제하는 명령)
C:\Documents and Settings\wssong>arp -a
No ARP Entries Found (arp cache가 삭제되고 아무런 정보가 없음을 보여준다)
C:\Documents and Settings\wssong> |
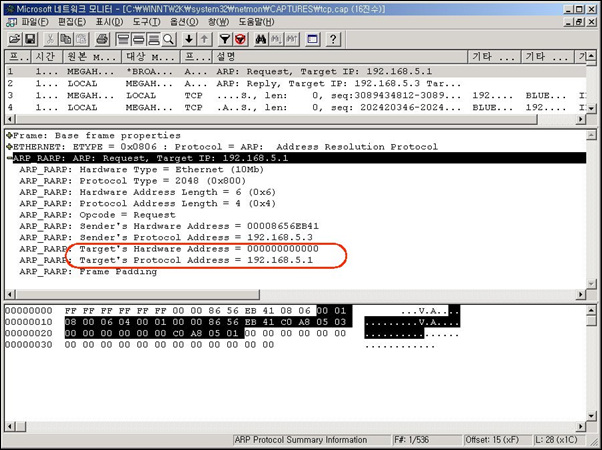
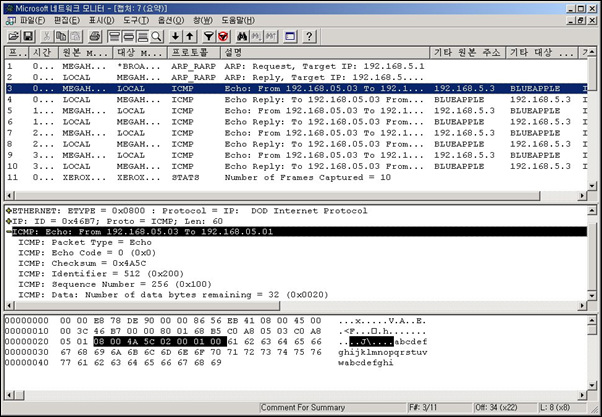
캡처한 그림은 ARP Request Broadcast 패킷이다. 그림에서 타원으로 표시한 부분을 보면 Target Protocol Address가 192.168.5.1로 되어 있고, Target Hardware Address가 000000000000 으로 되어 있음을 주목한다. 이것은 192.168.5.3 호스트가 192.168.5.1 IP Address를 사용하는 호스트의 네트워크 어댑터 카드의 MAC Address를 찾는 패킷임을 확인할 수 있다. 그 다음엔 당연히 192.168.5.1 호스트로부터 자신의 MAC Address를 알려주는 응답메시지가 와야 한다. 다음의 <그림1-12>에서 응답패킷을 확인할 수 있다.
<그림1-12. 네트워크 모니터로 캡처한 그림 – ARP Reply 패킷>
간단하지만 네트워크 모니터를 통해서 이러한 패킷들을 들여다 보면 꽤 재미있을 것이다. 책에서 보던 내용들을 그대로 네트워크에서 찾아볼 수 있을 테니 말이다. 그냥 외우던 것에 비하면 잊혀지지 않는 경험이 될 것이다.
-ICMP (Internet Control Message Protocol)
만일 패킷을 라우팅하는 도중에 문제가 발생한다면 어떻게 해야 할까? 그 때 바로 ICMP (Internet Control Message Protocol)의 역할이 필요해진다. ICMP는 원본호스트에게 에러를 보고하는 일을 한다. 예를 들어서 라우터를 통과하려는 패킷이 많아서 혼잡해 진다면, ICMP는 "Source quench Message"를 보내게 된다. Source quench Message는 호스트에게 전송속도를 늦춰줄 것을 요청하는 메시지이다. 또, 라우터가 혼잡한 상황에서 보다 나은 길(route)을 발견하였을 때 역시 redirect 메시지로써 다른 길을 찾도록 한다. 마지막으로 "Destination Host Unreachable"메시지를 전달할 때도 ICMP를 이용한다. "Destination Host Unreachable"은 회선이 다운되어서 라우팅 할 수 없거나 라우팅 테이블에 목적지의 네트워크 정보가 없을때 발생되는 메시지이다. 이상으로 ICMP의 역할 몇 가지를 알아 보았는데, 하는 일이 비슷하다는 것을 알 수 있다. 결국 에러를 처리하는데 초점이 맞춰져 있다.
ICMP는 IP가 패킷을 전달하는 동안에 발생할 수 있는 문제점을 보고하는 역할을 하는 프로토콜이다.
가장 쉽게 ICMP를 접할 수 있는 방법은 Ping을 이용해서 호스트와의 연결성을 테스트해 보는 것이다. 아래 상자안의 내용은 ping을 이용해서 테스트를 해본 결과이다. 첫 번째 IP로부터는 정상적인 응답이 왔지만, 두 번째 IP로부터는 응답이 오지 않았다. 이러한 일을 처리해주는 것이 ICMP이다.
|
C:\>ping 192.168.5.1
Pinging 192.168.5.1 with 32 bytes of data:
Reply from 192.168.5.1: bytes=32 time=361ms TTL=128
Reply from 192.168.5.1: bytes=32 time=430ms TTL=128
Reply from 192.168.5.1: bytes=32 time=300ms TTL=128
Reply from 192.168.5.1: bytes=32 time=460ms TTL=128
Ping statistics for 192.168.5.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 300ms, Maximum = 460ms, Average = 387ms
C:\>ping 192.168.5.2
Pinging 192.168.5.2 with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 192.168.5.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
C:\> |
위의 상황에서 네트워크를 캡처해 보았다. ICMP 패킷이 잡힌 것을 확인할 수 있다.
<그림1-13. 네트워크 모니터로 캡처한 그림 – ICMP 패킷>
캡처한 그림을 보면 ICMP라는 프로토콜로 보여지는 것이 총 8개이다. Ping 을 통해서 상대방 컴퓨터와 연결성을 테스트했을 때 응답이 4개가 왔었다. 요청 역시 4개가 날아갔던 것이다. 그래서 ICMP Echo 패킷이 4개, ICMP Reply 패킷이 4개. 총 8개의 패킷이 보여지게 되는 것이다.
-IGMP (Internet Group Message Protocol)
다른 프로토콜에 비해서는 비교적 쓰임새가 한정적인 프로토콜이다. IGMP는 멀티캐스트 메시지와 관련이 있다. IGMP를 사용하는 라우터는 멀티캐스트를 받아야할 호스트컴퓨터를 판단하고, 다른 라우터로 멀티캐스트 정보를 전달할 수 있다. IGMP패킷은 IP를 통해서 전달된다.
 [그림1]
[그림1] [그림2]
[그림2]  [그림3]
[그림3] [그림4]
[그림4]