2-4-1. CIDR - Subnetting
회사의 전체직원이 210명인 회사가 있다고 가정을 해 보겠다. 회사에서는 1인당 1대의 컴퓨터를 사용하고 있다. 회사에서는 보다 빠른 회선으로 업그레이드를 하면서 새로운 ISP로부터 인터넷 서비스를 받게 되고, 207.46.230.0 이라는 C Class Network ID를 할당받았다. 당신은 이 Network ID를 이용해서 회사의 클라이언트들에게 IP Address를 할당하는 작업을 해야 한다.
C Class Network ID 하나를 가지고 지원되는 호스트의 수는 최대 254까지이다. 회사의 전체 호스트 숫자가 210대이므로 C Class 하나만 가지면 충분히 지원할 수 있지만 이들
전체를 하나의 네트워크로 만들어 사용을 하기보다는 네트워크를 보다 작게 여러 개로 나누어 효율성을 기하고 싶다.
네트워크에 호스트수가 많아질수록 바로 브로드캐스트 통신이 문제가 되는데 네트워크에서는 이러한 브로드캐스트를 줄이는 방법으로 OSI 3계층 장비인 라우터를 통하여 네트워크를 여러개의 브로드캐스트 도메인으로 세그먼트하는 방법을 사용한다. 네트워크를 여러개로 나누면 각각의 네트워크에서 발생되는 브로드캐스트 패킷은 해당 네트워크에 한정되기 때문에 그만큼 효율적인 네트워크의 사용이 가능해 지는 것이다.
당신의 회사 역시 네트워크를 4개로 나눠서 한 세그먼트에 호스트의 숫자를 60대 미만으로 셋팅하고자 한다. 이러한 상황을 고려해 보겠다.
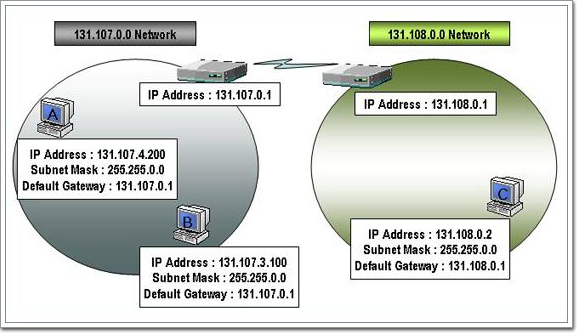
여기에서 당장에 혼란이 생긴다. 앞에서 서로 다른 물리적인 네트워크에서는 반드시 서로 다른 네트워크ID를 사용해야 한다고 했는데 당신은 ISP로부터 하나의 C Class 네트워크ID를 할당받았을 뿐이다. 이 하나의 네트워크ID를 4개의 세그먼트에 나눠서 차례대로 할당할 수는 있지만 그렇게 했을 때 이들 서로간에는 서로 통신을 할 수가 없게 된다. 같은 네트워크ID를 가지고 물리적으로 서로 다른 네트워크에 위치해 있으니 통신이 안 되는 것은 당연한 일이다.
ISP에 추가로 C Class네트워크 ID 3개를 요청했지만 추가비용을 요구한다. 거기다가 가만히 생각해 보니, 각각 254개를 쓸 수 있는 C Class ID를 3개 더 받아서 하나의 네트워크당 60개만 사용한다고 가정하니 나머지 194개씩의 IP는 버려질 수밖에 없는 노릇이다. IP Address의 낭비가 너무 심하다는 생각이 든다.
이것이 Class 체계의 IP Address가 가지는 맹점인 것이다. 보다 효율적인 방법은 없을까? 물론 있다. CIDR(Classless Inter Domain Routing)이라는 기법을 이용하여 IP Address를 보다 효율적으로 관리할 수 있다. 구현하는 방법은 의외로 간단하지만 처음 접근할 때 많이들 어려워하는 개념이다. 차근차근 접근해 보도록 하겠다. 실제로는 대기업 환경이나, ISP에서 쓰임새가 많은 기술이지만 시스템관리자에게는 상식적인 사항이 될 수 있다.
CIDR은 Subnetting과 Supernetting이라는 두가지로 구분해 볼 수 있다. 위의 예제의 경우에는 Subnetting이 필요한다. 할당받은 C Class ID는 네트워크 ID로 3개의 옥텟(24bit)을 사용하고 호스트ID로 1개의 옥텟(8bit)가 사용된다. 현재의 상황은 네트워크ID가 더 필요한 상황임을 고려하자. 해결방법은 호스트ID가 사용할 8bit중 일부를 네트워크ID용도로 전환하면 문제는 간단해 진다.
<그림2-21. CIDR기법- subnetting>
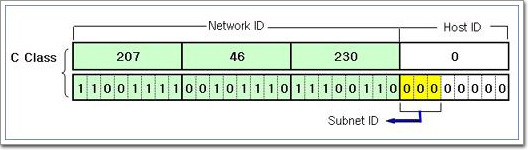
<그림2-21>에서 보듯이 호스트ID 8비트중에서 3비트를 네트워크ID 용도로 전환하여 사용하려고 한다. 이때 이 3비트를 "서브넷ID"라고 부르게 된다. 크게 본다면 네트워크ID에 포함될 수 있다. 좀 더 단계적으로 전체적인 계산방법을 알아보겠다.
2-4-2. Subnetting 계산 방법
Subnetting을 계산할 때 익숙해지면 암산으로도 가능해진다. 하지만 지금은 단계별로 접근해 볼 것이다. 다섯단계로 구분을 해서 계산을 해 볼 것이다. 차근차근 한단계씩 이해하고 넘어가도록 하자.
2-4-2-① 회사에서 필요로 하는 네트워크의 수 결정
서브넷팅을 하기전 가장 먼저 할 일은 회사에서 필요로 하는 네트워크의 수를 파악하는 일이다. 이때 고려할 사항은 당장 필요한 것도 중요하지만 향후 네트워크의 확장이 고려된다면 네트워크의 여유가 있을 때 그 부분을 미리 고려하는 것도 필요한 일이다. 위의 예제상황에서는 총 4개의 네트워크가 필요하다고 결정되었다.
2-4-2-② 필요한 네트워크ID를 만들기 위해 전환할 bit수의 결정
①에서 결정된 4개의 네트워크를 지원하려면 호스트ID가 사용하는 8개의 비트중에서 몇 개의 비트를 네트워크ID로 전환시켜 사용해야 할까? 22= 4라는 결과가 나오니 2개의 비트가 있으면 되겠다. ( 만일 6개의 네트워크가 필요하다면 어떻게 할까? 23=8이 되니 3개의 비트가 있으면 된다)
2-4-2-③ 서브넷 마스크(User defined Subnet Mask, Custom Subnet Mask) 계산
다음 해야 할 작업은 변경된 서브넷 마스크를 계산해야 한다. C Class의 기본서브넷 마스크는 255.255.255.0이었다. 이것은 C Class IP Address중에서 네트워크ID부분은 1, 호스트ID부분은 0으로 채운 결과 나온 값이었는데, 지금은 상황이 조금 달라졌다. 서브넷ID가 할당됨으로써 네트워크ID가 변동이 생겼으니 서브넷 마스크도 달라져야 한다. <그림2-22>에서는 변경된 서브넷 마스크가 계산되는 과정을 보여준다. 네 번째 옥텟의 호스트ID가 8비트에서 6비트로 줄어들고 상대적으로 네트워크ID가 2비트가 늘어났다. 일반적인 서브넷 마스크는 255.255.255.0 이었지만 호스트비트중 앞의 두 비트가 1로 바뀌었으므로 다시 계산하면 사용자정의된 서브넷 마스크는 255.255.255.192가 된다.
 <그림
<그림
<2-22.사용자 정의 서브넷 마스크 계산방법>
여기서 한가지 고려해 볼 것이 있는데, 서브넷 마스크가 바뀌었다는 것이 무엇을 의미할까? 앞에서 우리는 호스트가 TCP/IP통신을 하는 절차를 보았는데 그때 호스트는 목적지 호스트가 자신과 로컬에 있는지 원격지에 있는지를 결정하게 되었다. 그 방법으로 자신의 서브넷 마스크를 이용해서 자신과 목적지 호스트의 네트워크ID를 계산한 다음에 결과값을 살펴서 같으면 로컬, 다르면 원격지로 판단한다고 했다. 위에서 계산된 새로운 서브넷 마스크를 이용하면 하나의 C Class인 207.46.230.0을 사용하더라도 범위에 따라서 서로 다른 네트워크ID라는 결과를 얻을 수가 있게 된다. 결국 하나의 C Class ID로써 여러개의 네트워크ID를 가진 효과를 내게 되는 것이다.
2-4-2-④ 서브넷 ID 계산
<그림2-23. Subnet ID 계산>
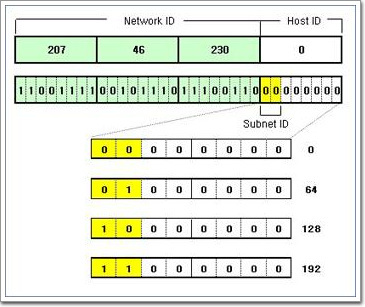
서브넷팅된 Network ID (Subnet ID)를 계산해야 한다. 207.46.230.0 네트워크 ID는 건드릴 수 없다. 호스트 비트인 8비트 중에서 앞의 2비트를 서브넷ID로 사용하고자 하기 때문에 <그림2-23>에서 노란색부분인 Subnet ID 2비트로써 생성할 수 있는 모든 경우의 수를 구해본다. 위의 그림에서 보듯이 00, 01, 10, 11 이라는 4가지 경우의 수가 나온다. 이것을 십진수로 전환하면 각각 0,64,128,192가 된다. 결국 서브넷 ID를 정리하면 다음과 같다.
- 207.46.230.0
- 207.46.230.64
- 207.46.230.128
- 207.46.230.192
2-4-2-⑤ 서브넷별 호스트ID의 범위 계산
이제 마지막 단계이다. 각 서브네트워크별 사용할 호스트ID의 범위를 구해야 한다. ④에서 구한 4개의 서브넷ID마다 생성할 수 있는 호스트ID의 범위를 구하기 위해 <그림2-24>를 참고해 보겠다.
<
그림2-24. Host ID의 범위 계산>
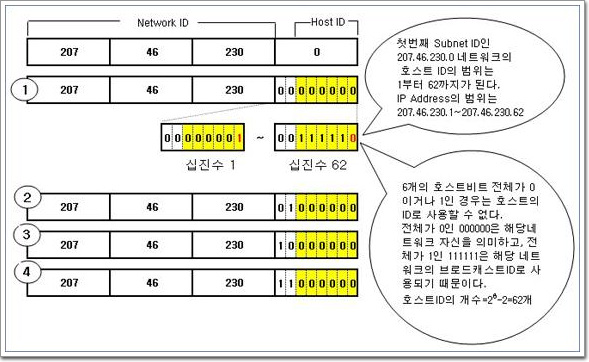
<그림2-24>의 ①번 서브넷을 예로 들면, 서브넷팅을 하기 전 호스트비트는 8개를 사용할 수 있었지만 서브넷팅을 하고 앞의 2비트를 서브넷 용도로 전환시켰기에 남은 것은 6비트가 있다. 서브넷ID인 처음의 00은 그대로 두고 나머지 6비트를 이용해서 생성할 수 있는 가장 작은 수와 큰 수를 각각 구하면 호스트ID의 범위가 나온다. 여기서 주의할 것은 호스트비트가 전체가 0이되는 경우와 전체가 1이 되는 경우 두 가지를 제외하여야 한다는 것이다.
이미 설명한 바 있지만 호스트비트 전체가 0이되는 주소는 해당네트워크 자신을 나타내고, 전체가 1이되는 수는 해당 네트워크의 브로드캐스트 ID로 사용되기 때문에 호스트에게는 할당할 수 없다. TCP/IP등록정보를 열고 이러한 주소를 입력해 보면 실제로 입력이 되지 않고 에러가 발생하는 것을 확인할 수 있다. 이것을 십진수로 전환해 보면 1과 62가 된다. 첫 번째 서브넷 ID인 207.46.230.0 네트워크에서 쓸 수 있는 호스트ID의 범위는 207.46.230.1부터 207.46.230.62까지로 총 62개의 호스트ID를 사용할 수 있는 것이다. (26-2=62개)
같은 방법으로 2~4번째 서브넷ID의 호스트ID의 범위를 구해보면 다음과 같다.
- 207.46.230.65~207.46.230.126
- 207.46.230.129~207.46.230.190
- 207.46.230.193~207.46.230.254
지금까지 몇단계를 거쳐서 서브넷팅 작업을 해 보았다. 단순히 IP Address의 클래스를 알아보았던 것에 비하면 조금 어렵다는 생각이 들 것이다. 하지만 분명히 필요성이 있는 것이기에 잘 익혀 두어야 한다.
2-4-3. CIDR 표기법
CIDR은 이진표기법을 사용한다. 위의 예제와 같이 서브넷팅된 상황이라면 207.46.230.2 라는 IP Address를 쓰는 호스트는 다음과 같이 표기할 수 있다.
이것은 207.46.230.2 IP Address중에서 26비트가 네트워크ID임을 가리켜 준다. 결국 Subnet Mask는 255.255.255.192라는 것을 알 수 있다.
지금까지 Subnetting의 개념과 구현방법에 대해서 알아보았다. 가장 많이 접할 수 있는 네트워크ID인 C Class를 통해서 예제를 만들어 보았다. B Class라면 더더욱 작업은 쉬워진다. 위의 방법을 토대로 하여 B Class 예제를 하나쯤 다루어 보기 바란다.
2-4-4. CIDR - Supernetting
Subnetting과는 반대의 개념으로 Supernetting을 구현할 수 있다. 상대적으로 중소규모의 회사 차원에서 수퍼넷팅이 구현될 필요는 없다. 개념적인 것을 알아두는 차원에서 다루어 보고자 한다. 한 회사가 192.168.1.0부터 192.168.5.0까지 5개의 네트워크ID를 사용하고 있다고 가정한다. 인터넷상에서 네트워크가 동작하기 위해서는 이 하나의 회사를 위해서 라우팅 테이블이 5개가 추가되어야만 할 것이다.
이경우 보다 효율적인 네트워크를 위해서 라우팅 테이블을 최적화하기를 원한다. 비록 C Class Network ID가 5개라고 할지라도 라우팅 테이블에서는 5개가 아닌 1개의 라우팅 경로만으로 이 회사의 네트워크를 지원할 수 있다면 그만큼 인터넷의 라우터들은 성능의 향상을 가져올 수 있을 것이다. 이런 경우에 수퍼넷팅을 이용하여 라우팅 테이블을 최소화 하는 것이 가능한다.
보다 간단하게 이해를 돕자면 위의 회사에서 5개의 네트워크ID를 사용하는데 물리적으로 하나의 네트워크에 이 5개의 서로 다른 네트워크ID를 할당해서 사용하고 싶다는 뜻이다. 네트워크를 하나로 통합하고 싶다는 것을 의미한다. 어떻게 하면 될까? 역시 서브넷 마스크에 달려 있다는 생각이 들 것이다. 비록 서로 다른 네트워크이지만 서브넷 마스크를 가지고 계산을 했을 때 같은 네트워크ID라는 결과가 나오도록 서브넷 마스크를 조절한다면 이들은 서로 같은 네트워크에 있는 셈이 될 테니까. 어째 생각하면 쉬운 것 같다.
이것을 가리켜서 수퍼넷팅이라고 부른다. 수퍼네팅된 서브넷 마스크를 구하는 방법은 <그림2-26>과 같다.

<그림2-26. 수퍼넷팅 계산방법>
255.255.248.0을 서브넷 마스크로 사용한다면 5개 네트워크의 어떠한 호스트ID를 사용하더라도 하나의 물리적인 네트워크에서 통신이 가능해진다. 예를 들어 192.168.1.100을 쓰는 호스트와 192.168.4.200을 쓰는 호스트가 물리적으로 하나의 세그먼트에 물려 있더라도 255.255.248.0을 사용하면 통신이 가능하다는 것을 말한다. 서로 같은 네트워크 ID라는 결과가 나오기 때문이다.
수퍼넷팅의 이해를 돕기 위하여 위와 같은 설명을 했으나 내부적인 네트워크에서는 위와 같은 처리를 할 이유가 없다. 이것은 어디까지나 인터넷 상에서 네트워크 경로를 최소화하여 보다 원활한 라우팅을 구현하는데 의의가 있다. ISP와 같은 대형 서비스 벤더에서 구현되는 방식이라고 이해하는 편이 좋겠다.
2-4-5. VLSM (Variable Length Subnet Mask)
마지막으로 한가지만 설명을 하고 마칠까 한다. 아래의 <그림2-27>을 보겠다. 이 회사는 192.168.200.0 C Class Network ID를 사용한다. 회사의 네트워크는 그림에서 보듯이 6개의 네트워크로 나뉘어 있는데 각 네트워크마다 서로 다른 노드(컴퓨터,라우터 등 하나의 포트를 차지하는 모든 디바이스를 총칭)를 가지고 있다. 이러한 상황에서 Subnetting을 통해서 6개의 네트워크에서 사용할 수 있는 ID들을 계산해 보고자 한다.

<그림2-27. 6개로 세그먼트된 192.168.200.0 네트워크>
위의 상황을 지금까지 배웠던 서브넷팅의 방법으로 계산하려고 하면 뭔가 맞지 않는다는 것을 알 수가 있을 것이다. 6개의 네트워크를 지원해야 하니, 호스트비트 8비트중 3비트를 서브넷 비트로 써야 할 것이다. 거기까진 좋은데 3비트를 서브넷비트로 사용했을 경우 호스트ID로 사용할 비트가 5비트가 되니 5비트를 가지고 만들 수 있는 호스트ID의 수는 25-2=30개가 된다. 그러면 <그림2-27>에서 60node가 있는 네트워크에는 IP Address가 부족하게 된다. 60개의 IP Address를 확보하려면 적어도 6비트는 필요하다.(26-2=62개) 8비트중 나머지 2개의 비트로 서브넷팅을 하면 되는데 문제는 그럴 경우 서브넷ID가 4개밖에 나오지 않는다는 것이다. '응 안되는구나.. '라고만 판단하면 길은 정해져 있다. 네트워크의 수를 줄이거나, 추가로 C Class Network ID를 더 확보하거나, 사설 네트워크로 가는 방법이 있을 것이다.
그렇지만 회사의 전체 호스트수를 더해봐도 194대밖에 되지 않는데 최대 254개의 호스트를 지원하는 C Class 하나로써 이것을 지원하지 못한다는 것은 뭔가 석연치 않다. 이러한 경우 당신은 Subnetting을 효율적으로 운영할 수 있다. 각각의 네트워크에 필요한만큼만 호스트ID를 할당하는 방법을 사용하는데 방법은 다음과 같다.
전체의 서브넷ID를 한꺼번에 계산해서는 안된다. 필요한 부분마다 각각 계산을 해 나가는데 필요한 네트워크ID를 지원하기 위해 필요한 비트수를 계산하는 것이 아니라 필요한 호스트ID를 지원하기 위해 필요한 비트수를 먼저 계산한다. 호스트의 수가 많이 필요한 서브넷부터 먼저 계산해 나가는 편이 좋다.
(1) 60개 호스트를 지원하기 위한 서브네팅
- 60개의 호스트를 지원하기 위해 필요한 호스트 비트수 = 6개 (26-2=62)
- 서브넷 마스크는 11111111.11111111.11111111.11000000 (남은 2비트로 서브네팅)
- 서브넷ID는 서브넷ID중 낮은 자리수의 십진수를 구하면 -> 64 (64씩 증가하는 서브넷)
- 호스트ID의 범위 2개를 구하면 -> 192.168.200.1~62, 192.168.200.65~126 / 26
(2) 30개 호스트를 지원하기 위한 서브네팅
- 30개의 호스트를 지원하기 위해 필요한 호스트 비트수 = 5개 (25-2=30)
- 서브넷 마스크는 11111111.11111111.11111111.11100000 (남은 3비트로 서브네팅)
- 서브넷ID는 서브넷ID중 낮은 자리수의 십진수를 구하면 -> 32 (32씩 증가하는 서브넷)
- 호스트ID의 범위 2개를 구하면 -> 192.168.200.129~158, 192.168.200.161~190 / 27
( 1~127까지는 이미 앞의 네트워크에서 사용되었음을 유의한다.)
(3) 12개 호스트를 지원하기 위한 서브네팅
- 12개의 호스트를 지원하기 위해 필요한 호스트 비트수 = 4개 (24-2=14)
- 서브넷 마스크는 11111111.11111111.11111111.11110000 (남은 4비트로 서브네팅)
- 서브넷ID는 서브넷ID중 낮은 자리수의 십진수를 구하면 -> 16 (16씩 증가하는 서브넷)
- 호스트ID의 범위 1개를 구하면 -> 192.168.200.193~206 / 28
( 1~191까지는 이미 다른 네트워크에서 사용되었음을 유의한다.)
(4) 2개 호스트를 지원하기 위한 서브네팅
- 2개의 호스트를 지원하기 위해 필요한 호스트 비트수 = 2개 (22-2=2)
- 서브넷 마스크는 11111111.11111111.11111111.11111100 (남은 6비트로 서브네팅)
- 서브넷ID는 서브넷ID중 낮은 자리수의 십진수를 구하면 -> 4 (4씩 증가하는 서브넷)
- 호스트ID의 범위 1개를 구하면 -> 192.168.200.209~210 / 30
( 1~207까지는 이미 다른 네트워크에서 사용되었음을 유의한다.)
위와 같이 계산을 하여 아래의 <그림2-28>과 같이 IP Address를 배치하는 결과를 얻은 것이다. 가만히 살펴보면 이들 서브넷들은 앞에서의 일반적인 서브네팅과는 달리 서브넷마다 서브넷 마스크가 다르다는 것을 알 수가 있는데 이러한 기법을 가리켜서 "가변길이서브넷"(VLSM; Variable Length Subnet Mask) 기법이라고 한다.
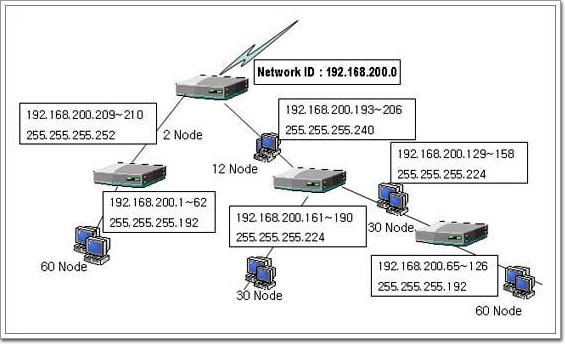
<그림2-28. VLSM을 이용한 서브네팅>
아직 서브넷팅이 익숙하지 않기 때문에 한꺼번에 4개의 서브넷팅이 부담스러울 수 있겠으나, 위와 같은 방법을 이용하면 보다 효율적인 IP Address 관리가 가능해진다. 전체 호스트에게 IP Address를 할당하고도 아직 192.168.200.212~254까지의 여분이 남아 있다. 추가로 네트워크가 더 생기더라도 할당할 여유가 있게 되었다. 앞의 서브넷팅을 완전히 이해하고 나면 VLSM의 필요성, 방법 등을 이해하기가 쉬울 것이다.